
What is Artificial General Intelligence (AGI)? An Explainer for Policymakers
-
Explainer
-
AI Governance
Artificial General Intelligence (AGI) refers to AI systems that perform well on a wide range of cognitive tasks. More demanding AGI definitions also require that these AI systems can learn and reason, that they can physically manipulate objects in the real world, and that they produce economically valuable work.
Building AGI is the declared goal of many of the world’s most valuable publicly-traded companies, from Alphabet to Meta to Amazon, as well as leading private AI companies such as OpenAI. In this context, the term AGI is diffusing from Silicon Valley jargon into the lexicon of policymakers and international AI governance bodies.
We welcome the increasing discussion around AGI because greater AI capabilities entail both significant positive and negative consequences for society. Understanding what AGI entails is crucial to designing governance structures to steer its safe and beneficial development.
However, AGI is a confusing term. Some AI experts claim that we already have AGI, others predict AGI in 18 months, others by 2033, and others by 2047. In principle, they could all be right. This blog post explains why the term AGI can mean different things to different people and how the companies building AGI are thinking about different levels of AGI.
There are many different definitions of AGI
The term AGI originated from a 2007 book, specifically as part of a dichotomy with narrow AI. The idea was that narrow AI systems are “programs that demonstrate intelligence in one or another specialized area”, whereas AGI is “a software program that can solve a variety of complex problems in a variety of different domains”.
Over the years, dozens of different tests have been suggested to measure when an AI qualifies as AGI. It makes sense to think of them in four main clusters:
- Language-related tests (✅): Good performance on language tests is indicative of a broad knowledge of concepts and relations. The best-known language test is the Turing Test: Human evaluators ask questions via text to humans and an AI that pretends to be a human. If the human evaluators can’t distinguish between humans and the AI, the AI has passed the test. Further language-related tests focus on linguistic complexity, linguistic creativity, text compression, and reading comprehension. Language used to be one of the grand challenges of AI, but with the advent of large language models, AI systems pass most language-related AGI tests.
- Fluid intelligence tests (⏳): AI may perform well on most tests by memorizing lots of data. In contrast, if it achieved the same performance through pure reasoning, this would be much more impressive. The Abstraction and Reasoning Corpus (ARC) poses challenges that avoid the possibility of memorization and is the main fluid intelligence test for AI. The ARC-AGI Grand Prize has not been claimed yet. However, there has been significant progress since the development of OpenAI’s o1 and the rise of reasoning models.
- Physical manipulation tests (❌): These tests do not focus solely on cognitive tasks, but on manipulating objects in the real world. The best-known test is the Total Turing Test, a test in which an AI must be able to do everything that humans can do in the real world. More narrow versions of this are the coffee test, working as a cook in an arbitrary kitchen, assembling IKEA furniture, or assembling a toy automobile. Physical manipulation requires a range of sensors, actuators, and cognitive skills. It is arguably also more safety-critical than purely cognitive tasks. AGI tests for general-purpose robotics have not been passed yet.
- Economically valuable work (❌): A last set of AGI definitions focus on economic impact. The archetypal representation of this cluster is Nilsson’s employment test, which argues that AGI must be able to perform the jobs that humans do in the economy. Similar approaches have been taken by Katja Grace et al., OpenAI, Ajeya Cotra, and Mustafa Suleyman. On the one hand, focusing on economic impact has the advantage of strong validation of significance in the real world. On the other hand, the economic impact of technologies is a lagging indicator of AI capabilities, and attribution of automation and economic growth to a single technology may not always be easy. AGI definitions focusing on economic impact have not been met yet.
Large language models already meet some AGI definitions
Some, such as Blaise Agüera y Arcas and Peter Norvig, make the case that current frontier AIs, such as ChatGPT, should be thought of as AGI. They highlight five factors that support this interpretation:
- Range of topics: Frontier models are trained on hundreds of gigabytes of text from a wide variety of internet sources, covering any topic that has been written about online.
- Range of tasks: Frontier models can answer questions, generate stories, summarize, transcribe, translate, explain, make decisions, do customer support, call out to other services to take actions, etc.
- Range of input and output modalities: The most popular models or groups of models are increasingly multimodal, operating on text, images, audio, and video as inputs, and generating text, images, audio, and video as outputs.
- Range of languages: English is over-represented in the training data of most systems, but large models can converse in dozens of languages and translate between them, even for language pairs that have no example translations in the training data.
- Some ability to learn: Frontier models are capable of “in-context learning,” where they learn from a prompt rather than from the training data. In “few-shot learning,” a new task is demonstrated with several example input/output pairs, and the system then gives outputs for novel inputs.
The inherent emphasis in the term AGI is on generality, not on a specific level of capability or autonomy. In that sense, calling large language models “narrow AI” seems inadequate. In the words of Geoffrey Hinton: “Things like ChatGPT know thousands of times more than any human, in just sort of basic common-sense knowledge”.
Some AGI definitions are very demanding and unlikely to be met soon
While the term AGI is sometimes used synonymously with “human-level AI”, it is important to emphasize that some AGI tests de-facto require much more than matching human intelligence. The fundamental asymmetry in some AGI definitions or tests is that to pass them, they require AI to perform at least as well as an average human, a professionally specialized human, or even the best professionally specialized human on every task from a very large range of tasks.
Evidence of AI progress so far points towards a “jagged technological frontier”, in which AI systems match human levels and even vastly exceed humans at some tasks but remain lacking in other aspects. If what we count is not the average performance over a large set of tasks, but only the relatively weakest AI performance and the relatively strongest human performance, then AI systems will de facto perform at superhuman levels before qualifying as AGI.
AGI companies think in terms of “levels of AGI”
Now that we have seen the range of AGI definitions, we can see why headlines like “AI expert says AGI by 2030” can be confusing. Indeed, if we look at the previously referenced predictions of AGI by the end of 2026, by 2033, and by 2047, they all use different definitions.
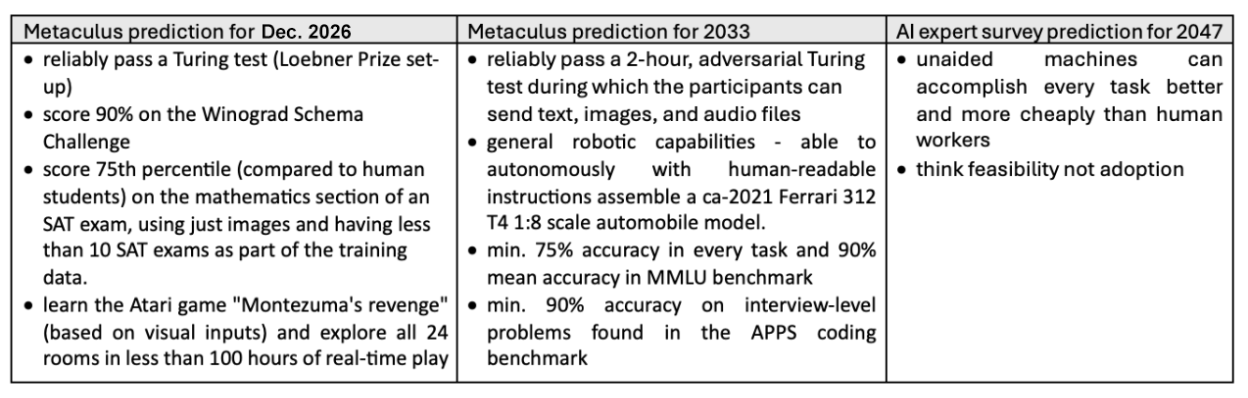
The companies building AGI systems have all understood that the definitional ambiguity of AGI is a challenge and have created their own “levels of AGI” based on the performance and risks associated with advanced AI systems.
A) Deepmind’s Levels of AGI
In 2024, a group of Google Deepmind researchers published a categorization that distinguishes between different levels of AGI. This group notably includes Shane Legg, the co-founder of Deepmind, who coined the term Artificial General Intelligence, and has written a PhD on intelligence definitions.
The group concluded that current large language models should logically fall into that category of AGI. However, while the authors use the term AGI for all systems that have a wide range and at least unskilled human performance, they also introduce distinct levels of AGI based on performance. So, current frontier AIs are AGI but only “Level 1 – Emerging AGI”. Other AGI subcategories would require higher levels of performance.
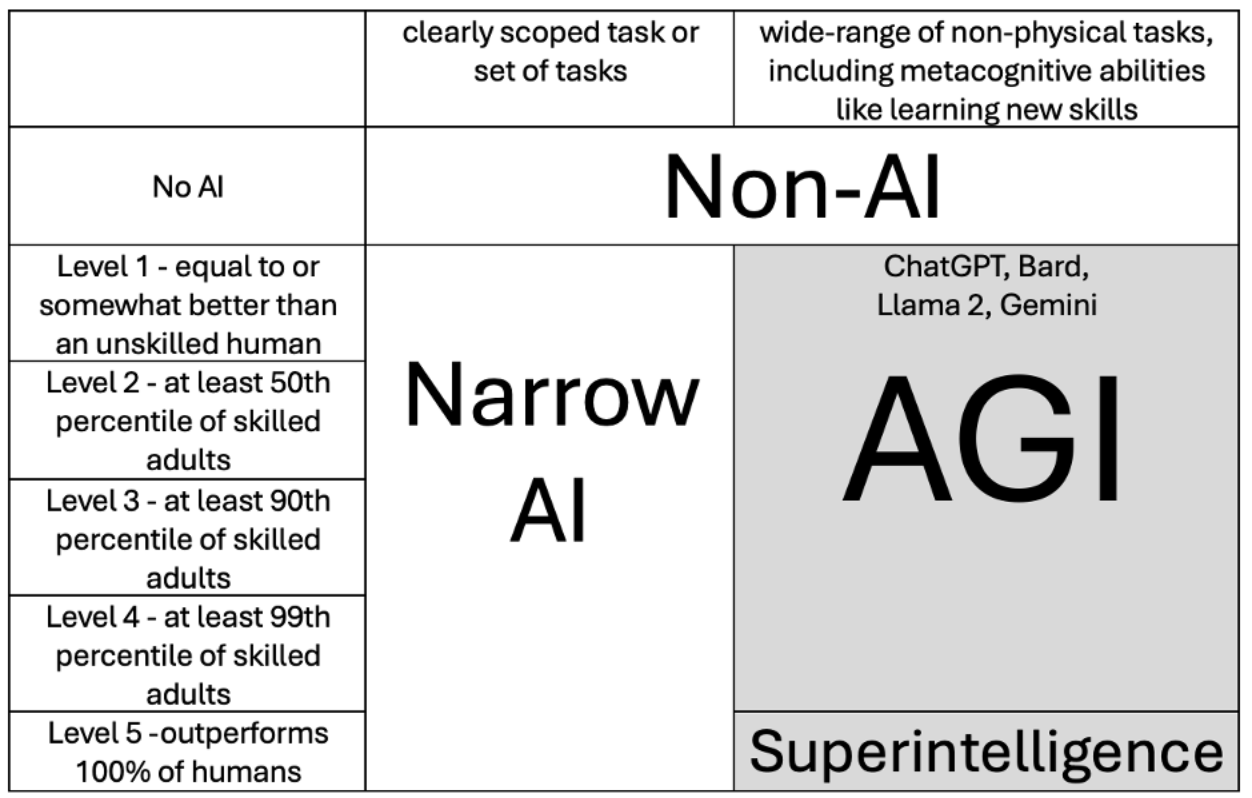
B) OpenAI’s Levels
OpenAI has not published any levels of AGI. However, based on reporting from Bloomberg, they appear to be using the following internal framework:
- Level 1 – Chatbots: Includes all large language models that can engage in conversation, answer questions, and perform basic tasks using natural language.
- Level 2 – Reasoners: Refers to AI systems capable of more advanced reasoning, problem-solving, and fluid intelligence beyond scripted responses. According to OpenAI its o1 model, which uses chain-of-thought, was the first reasoning model.
- Level 3 – Agents: Refers to AI systems that can take actions in the world, interact with software or environments autonomously, and complete complex tasks without continuous human guidance.
- Level 4 – Innovators: AI systems capable of generating novel ideas, conducting original research, or creating entirely new content, solutions, or technologies.
- Level 5 – Organizations: AI systems with the capacity to coordinate, delegate, and manage multiple agents or functions, resembling the behavior and intelligence of a human-run organization.
According to media reports, OpenAI also has a legal agreement with Microsoft, in which Microsoft loses access to OpenAI’s tech if the latter develops AGI, which has been defined as AI systems able to generate 100 billion USD in profits.
C) Anthropic’s AI Safety Levels
As part of its Responsible Scaling Policy Anthropic has defined AI Safety Level (ASL) standards. These levels, inspired by the biosafety levels of research laboratories that handle dangerous pathogens, define a set of technical and operational measures for safely training and deploying frontier AI models.
- ASL-1 is required for AI systems which pose no meaningful catastrophic risk.
- ASL-2 is required for AI systems with early signs of dangerous capabilities (e.g. instructions on how to build bioweapons but with insufficient reliability or not providing info that a search engine couldn’t).
- ASL-3 is required for systems that substantially increase the risk of catastrophic misuse compared to non-AI baselines or that show low-level autonomous capabilities.
- ASL-4+ is not defined yet, but this would cover systems that can cause catastrophic risk and have autonomy.
At present, all Anthropic models must meet the ASL-2 deployment and security standards. In May 2025 Claude Opus 4 became the first model that requires ASL-3 in Anthropic’s own assessment.
We are moving towards a world shaped by AGI
Given the definitional ambiguity, there is no sharp dividing line between artificial narrow intelligence and artificial general intelligence. There can be specific focusing events and inflection points but there will likely never be a universal agreement on what qualifies as the first AGI system without additional qualifications (much like there wasn’t a strong agreement on what qualified as the first AI or the first computer). As such, AGI is not a specific point in time.
Instead, we can observe a trend towards AI systems with more general intelligence, and the default expectation should be that the number and levels of AGI systems will increase over time. In that sense, we are moving towards an “age of AGI”, in which the trajectory of humanity is increasingly shaped by AGI systems.
We need to increase societal readiness for AGI
AI companies have voluntarily committed to frontier AI safety frameworks to responsibly increase their own technical mitigation measures as we reach more advanced AGI levels. However, not all mitigation and governance measures can or should be taken by companies.
Ideas for broader societal readiness for AGI include the framework of the former head of AGI Readiness at OpenAI or the “AGI Readiness Index” created by the prediction company Metaculus. To provide a specific example, if new AI models increase the risk of bioterrorism, preventive measures need to be strengthened across bottlenecks, such as synthesis screening, not just at the level of AI models. Similarly, it is up to governments to design tax systems, pension systems, and social security systems that can withstand potentially disruptive impacts of AI models on labor markets.
In short, AGI means different things to different people. Hence, especially when talking about predictions of AGI timelines, it is important to be specific. At the same time, the trend has a clear direction and points towards more and more powerful AGI systems over time. It is not just up to AI companies, but also up to national governments and international organizations to ensure that we improve the societal readiness to handle the risks and opportunities of higher levels of AGI.
***
This text is an adapted version of a blog post on Kevin Kohler’s blog, Machinocene.


